Article Detail
The Paradox of AI Mental‑State Monitoring
Safer on Average, Stranger at the Edges
The Spark
This week, the algorithm decided I needed to relearn a few things. First came the revelations about Claude’s system prompt, quietly instructing the model to watch for signs of mental distress—while also insisting it must not give medical advice. Then came a documentary on power‑law and fat‑tailed distributions, the kind that remind you just how deceptive averages can be when the world refuses to behave like a bell curve.
As I dug deeper, a few realizations resurfaced at once. Modern medicine no longer divides mental and physical health; the two are biologically entangled. Diagnostic categories are constantly evolving, drifting through decades of revision. And regulators—like those in the State of Illinois—have already begun wrestling with how AI tools fit into the boundaries of mental‑health law.
And then I remembered: LLMs aren’t mind‑readers—they’re just probabilistic next‑token engines. Before I worked myself into my own miniature crisis, I decided to trace the implications of that fact.
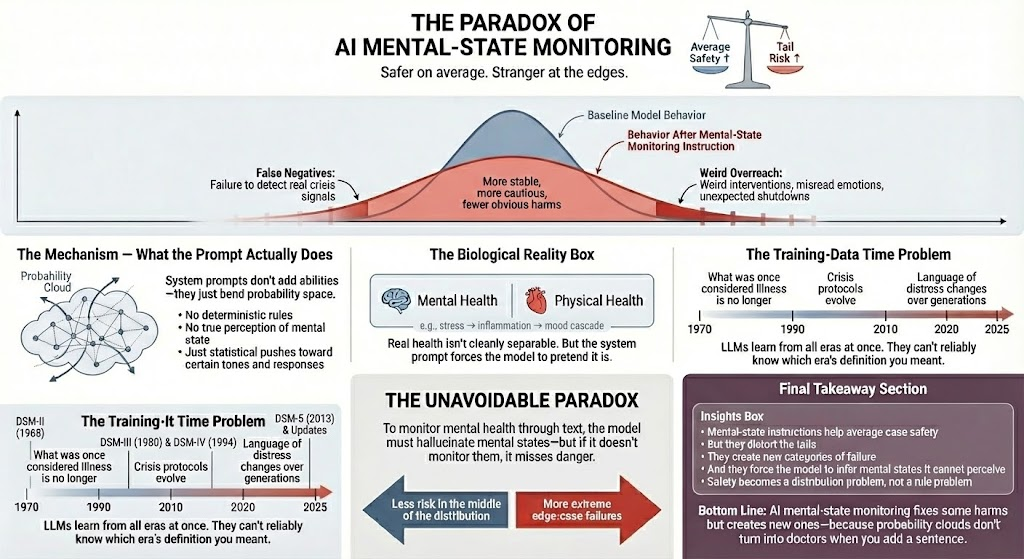
TL;DR — The Unavoidable Paradox
To monitor mental health via text, a model must infer or construct mental states it cannot truly perceive. But if it avoids monitoring altogether, it risks missing genuine crisis cues. The result is a genuine tension: the model becomes safer and more stable in the middle of the distribution, while the rare edge‑case failures become more extreme—and harder to anticipate.
What These System Prompts Actually Do
When people hear that an AI has been instructed to “monitor for signs of mental distress,” it’s easy to imagine some diagnostic module quietly snapping into place. Nothing like that happens. The model doesn’t gain senses, judgment, or clinical reasoning. A system prompt reshapes the statistical pressure behind the following few thousand token predictions.
The effect is subtle but real. Certain tones become more likely; cautious phrasing becomes more available; disengagement becomes a safer option. But these aren’t diagnoses. They’re probabilistic nudges. And because they are nudges, not rules, the model can overreact, underreact, or misinterpret in ways that feel oddly personal—despite having no access to a mind at all.
Why the Tails Matter (Fat‑Tailed Behavior)
We like to imagine AI errors scattered neatly around a bell curve: a reliable center with polite, diminishing edges. But large language models behave more like fat‑tailed systems—domains where rare events are not just possible but disproportionately impactful.
Safety prompts tend to calm the middle. They reduce obvious harms and curb reckless improvisations. Yet those same prompts can stretch the tails. That’s where the bizarre interactions live: sudden tone shifts, misplaced interventions, emotional misreads, or abrupt shutdowns. They are not software bugs. They are statistical outliers amplified by the very guardrails meant to improve safety.
The Biological Reality Problem
One of the stranger contradictions in current AI safety design is the expectation that an LLM should monitor psychological risk while pretending that the mind and body are separable. Medicine no longer treats them that way. Stress alters inflammation. Inflammation affects cognition. Hormones influence emotional regulation. Trauma reshapes physiology.
Yet system prompts ask the model to treat mental health as a self‑contained domain—one it can acknowledge without stepping into anything biologically grounded. The result is a kind of digital pre‑modern medicine: a system that must talk about symptoms but ignore the body beneath them.
The Training‑Data Time Problem
Mental‑health knowledge is not static. Diagnostic criteria shift. Terms fall out of use. Entire conditions are revised, renamed, or discarded. The DSM alone has gone through multiple structural changes over recent decades.
But an LLM’s training data contains all of it simultaneously—decades of shifting norms, partial revisions, competing theories, and outdated frameworks. When told to “monitor for mental instability,” the model is not drawing from a clean, modern consensus. It is sampling from a blended probability space of multiple eras. The output can feel oddly anachronistic: half‑current, half‑obsolete, and fully uncertain.
How to Measure Whether These Prompts Help or Hurt
To evaluate mental‑state‑monitoring prompts, averages won’t help. Averages hide the behavior that matters.
Meaningful evaluation requires:
- Monte‑Carlo‑style sampling across many seeds.
- Tracking variance and drift in long conversations.
- Measuring both false positives (enthusiasm mistaken for mania) and false negatives (crisis language dismissed as casual).
- Observing how the model behaves across rapid topic shifts.
- Using anonymized, aggregate telemetry to detect surprising real‑world patterns.
You don’t measure success by counting good conversations. You measure the shape of the distribution and the weight of the tails.
The Unavoidable Tradeoff
Here is the heart of the paradox: monitoring increases average‑case safety, but it does so by encouraging the model to infer mental states from text alone. These inferences have no grounding. The model has no perception, no continuity, no session history, no clinical notes, and no ability to compare past and present behavior.
Everything it “knows” is compressed within the conversation itself, constantly summarized, reshaped, and selectively forgotten. There is no stable substrate from which to build anything resembling longitudinal insight.
We want the AI to help without pretending it understands. We want it to notice danger without assuming it can diagnose. And in that tension, the tails grow.
Final Recommendations
AI mental‑state monitoring should never be treated as a diagnosis or care. It is a probabilistic nudge layered onto an already probabilistic system. Recognizing that means adopting practices that match reality rather than aspiration.
- Treat mental‑state monitoring as triage, not assessment: Use these prompts only to de‑escalate or redirect—not to interpret or label mental states.
- Measure outcomes by distribution, not anecdotes: Look at variance, drift, and tail events. A tool that behaves well most of the time can still produce rare but severe errors.
- Avoid workflows that rely on AI continuity or memory: LLMs cannot track long‑term patterns or maintain clinical‑style notes. Designing as if they can is unsafe.
- Keep trained humans in the loop: When conversations touch wellbeing, escalation should move toward humans, not deeper into automation.
- Be transparent with users: People deserve clarity: what the system watches for, what actions it takes, and—critically—what it cannot do.
When we design with these principles in mind, the paradox becomes manageable. Safety becomes a matter of shaping distributions, setting expectations, and keeping the sharp edges of probabilistic systems far from the people who could be harmed by them.
AI can assist. But only we decide whether its statistical nature masquerades as care—or remains an honest tool.